스캔본이나 사진으로 찍은 PDF를 AI에 넣었다가, 표가 와르르 무너져서 한숨 쉬어보신 분들.
글자는 그럭저럭 읽어도 표가 깨지고 읽는 순서가 뒤섞이면, 결국 사람이 다시 문서를 정리하게 되죠.
Datalab이 만든 Surya에 신문·논문·손글씨 노트를 통째로 던져봤습니다.
글자만 뽑는 게 아니라 표는 표대로, 제목·그림·문단은 제자리로, 읽는 순서까지 살려서 정리해 내놓더라고요.
이게 다 모델 하나 안에서 돌아갑니다. 심지어 무료로 받아서 직접 돌릴 수 있는 오픈소스예요.
2/6 표가 안 깨집니다
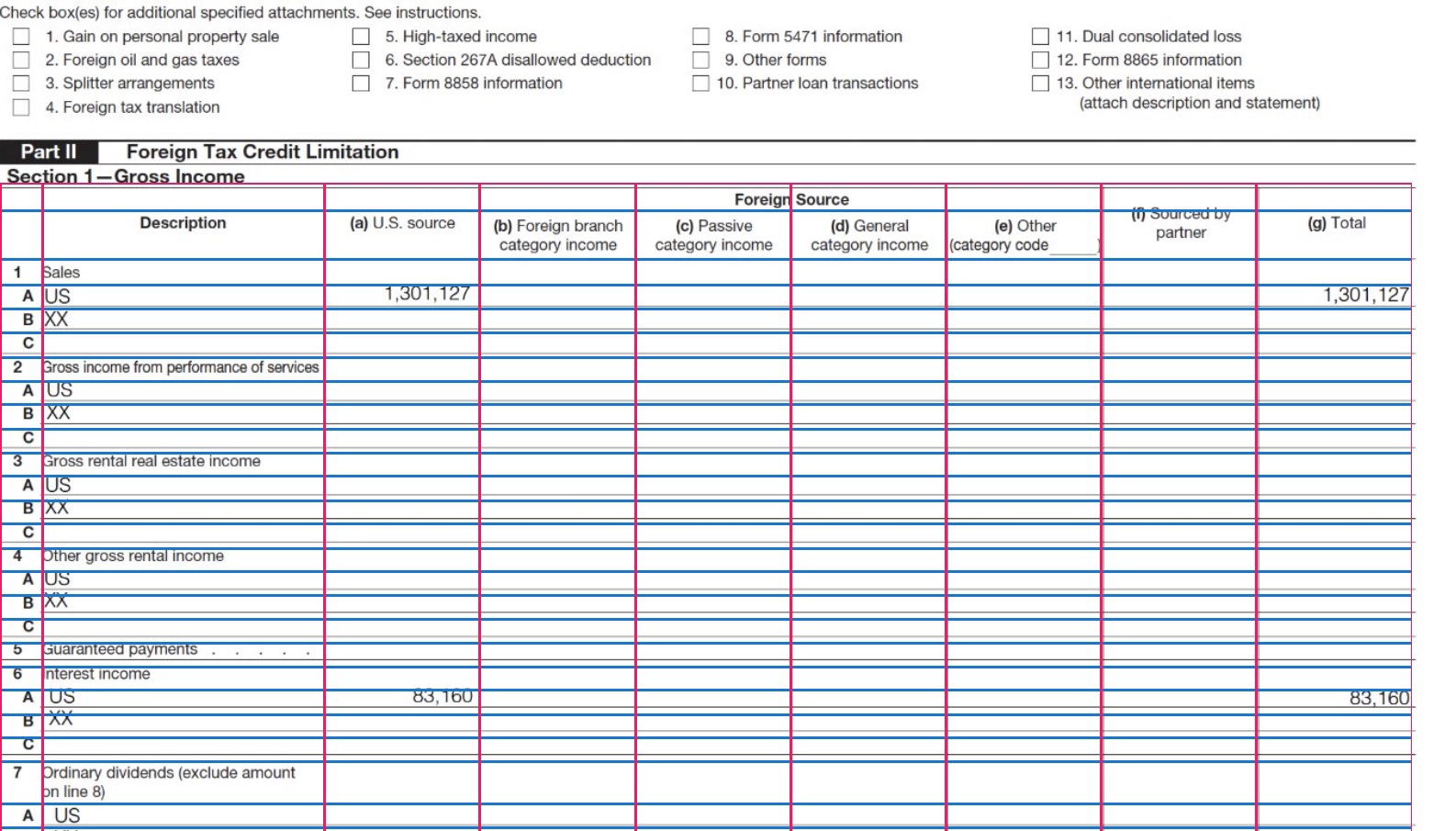
칸이 빽빽하게 나뉜 세무 양식 같은 것도, 행과 열과 셀을 하나하나 잡아서 그대로 HTML 표로 떨궈줍니다.
표 안 숫자가 엉뚱한 칸으로 새는 게 OCR의 고질병이었는데, 그 칸 구조를 통째로 읽어냅니다.
3/6 "이건 제목, 이건 그림, 이건 참고문헌"
문서를 글자 덩어리로만 보지 않아요.
제목·본문·캡션·그림·표·참고문헌을 구분해서 이름표를 붙이고, 어디서부터 어떤 순서로 읽어야 하는지까지 매겨줍니다. 단이 여러 개인 논문이나 신문도요.

4/6 손글씨에 수식까지
키보드로 친 글자만 되는 게 아닙니다.
손으로 갈겨쓴 수학 노트를 넣으면 행렬이나 수식까지 알아보고, LaTeX로 정리해서 내놓습니다.

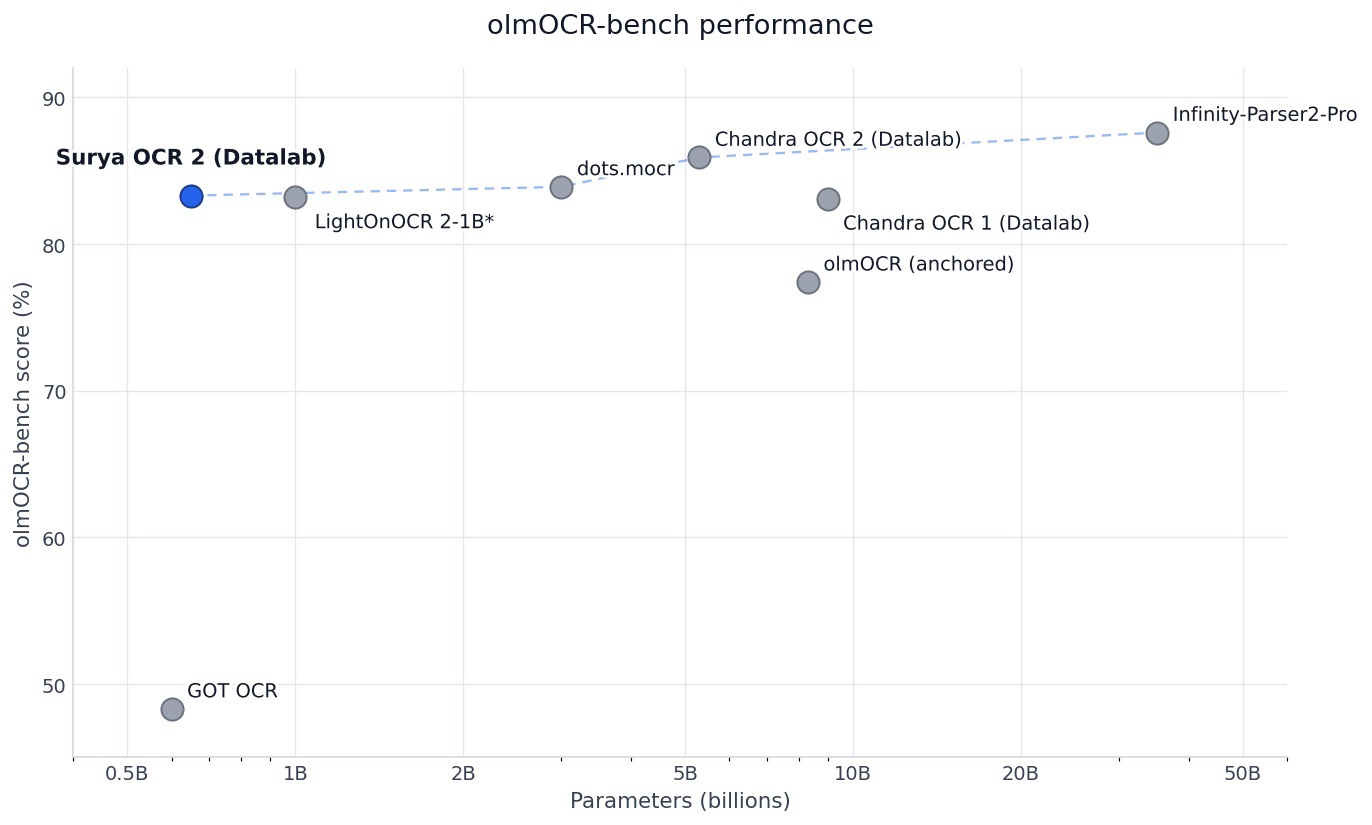
5/6 근데 이게 650M짜리예요
흐릿한 작은 글씨도, 빽빽한 표도, 영어 아닌 90여 개 언어 문서도 두루 처리합니다. olmOCR 벤치에서는 83.3%, 자기보다 수십 배 큰 모델들과 어깨를 나란히 하는 점수죠.
이런 문서 파싱은 보통 거대 모델을 클라우드에 올려야 하는 일이었죠. 그걸 개인 PC에서도 돌릴 만한 크기로 그 자리에 올려놨다는 게 진짜 포인트예요.
코드는 누구나 가져다 쓰게 열려 있고, 모델 자체도 연구·개인이나 작은 회사는 무료입니다. 회사 서비스에 붙일 거면 상업 라이선스 범위만 먼저 확인하면 돼요.
6/6 source: https://github.com/datalab-to/surya